
はじめに
みなさんこんにちは!日常生活や業務の中で、大規模言語モデル(LLM)を使って質問に答えてもらったり、簡単なタスクを補助してもらうことに慣れている方も多いのではないでしょうか。LLMの能力は確かに便利ですが、皆さんの中には、「単純な質問への回答」という用途に留まってしまっている方も多いかもしれません。しかし、これらの技術の潜在能力は、はるかに広がりがあります。
今日は、そんなLLMの能力をさらに引き出す「ReAct」というユニークな方法についてご紹介します。この手法の名前は、「Reasoning(推論)」と「Action(行動)」を組み合わせたことに由来しています。この方法を使うと、LLMは単なる質問応答に留まらず、複雑な問題の解決や自己修正が可能になります。
まず、ReActの基本的な考え方を理解するために、人間の行動の仕方と比較してみましょう。たとえば、何かタスクを進めるとき、私たちは次のようなステップを繰り返します。
考える(推論)
現状を観察し、次に何をすべきか考える。
行動する
考えたことに基づいて具体的な行動を起こす。
結果を観察する
行動の結果を確認し、それを次の推論に活かす。
このプロセスをAIに応用したものがReActの基本構造です。
ReActを例で考えてみる
スープを作る場合を想定してみます。人間であれば次のような手順で進めるでしょう。
考え1(推論)
スープを作るためには材料(野菜、肉、塩など)を用意し、お湯を沸かす必要がある。
行動1
お湯を沸かす。
観察1
お湯が沸騰している。
ここまでで、お湯を沸かす準備が整いました。
考え2(推論)
次に、沸騰したお湯に材料を入れる必要がある。
行動2
鍋に肉、野菜、塩を入れる。
観察2
スープが完成に近づいているが、少し水が少ないようだ。
問題が発生した場合も、次のように対応します。
考え3(推論)
水を追加しないとスープが美味しくならない。
行動3
鍋に水を追加する。
観察3
水の量が適切になり、スープが美味しそうに見える。
最後に仕上げの段階です。
考え4(推論)
スープが美味しくなるには15分間煮込む必要がある。
行動4
15分間待つ。
観察4
スープが煮え立ち、完成した。
このプロセスをAIが模倣
ReActは、このように「推論」と「行動」を組み合わせた手法で、AIが環境を観察しながら最適な判断をし、複雑なタスクを遂行できるようにします。この方法の特徴は、タスクを進めながらリアルタイムで改善を図ることができる点にあります。
結果として、ReActを活用すれば、AIは複雑なタスクを柔軟にこなし、問題が発生しても迅速に修正できるようになります。
ReAct エージェント
ReAct エージェントのコンポーネント
ReActエージェントは、2022年に発表された論文「ReAct: Synergizing Reasoning and Acting in Language Models」に基づいて開発された手法です。前述したように、この論文では、大規模言語モデル(LLM)を活用し、推論(Reasoning)と行動(Acting)を組み合わせてタスクを解決する方法が提案されています。
Chain-of-Thought (CoT) アプローチ
Chain-of-Thought (CoT) は、AIモデルが複雑な問題を解決するためのステップを順を追って考えられるようにする手法です。このアプローチでは、大きな問題をいくつかの小さなステップに分け、各ステップを順番に解決していきます。その結果、モデルが一度に多くを考えすぎず、論理的に正確な結果を導き出すことが可能になります。
CoT アプローチの基本
問題の分割
複雑な問題を、小さくて簡単に処理できるステップに分けます。
逐次的思考
ステップごとに結果を出し、それを次のステップに活用します。
最終結果の到達
各ステップを積み重ね、最終的に正確な答えを導きます。
実際の例
質問
ある店舗が製品を100ドルで販売しています。その店舗が20%の割引を適用し、その後10%値上げした場合、最終的な製品価格はいくらですか?
CoT アプローチを使った解き方
ステップ1: 割引後の価格を計算
まず、100ドルの製品に20%の割引が適用されます。
20%割引とは、元の価格の20%(100ドル × 0.2)を引くことを意味します。
計算:
100×(1−0.2)=80
割引後の価格は 80ドル です。
ステップ2: 値上げ後の価格を計算
次に、割引後の価格に10%の値上げが適用されます。
10%値上げとは、割引後の価格の10%(80ドル × 0.1)を追加することを意味します。
計算:
80×(1+0.1)=88
値上げ後の価格は 88ドル です。
結果
最終的な製品価格は 88ドル になります。
CoT アプローチのポイント
1つずつ進める
全体の問題を一度に解こうとせず、まずは割引、その後値上げという順序で進めます。
結果を活用する
割引後の計算結果を次の値上げ計算に活用しています。
このように、CoTアプローチを使うと、複雑な計算や問題をわかりやすく段階的に解決することができます。
ReAct エージェントの「ツール」
ReAct エージェントの「ツール」とは、AIが外部の情報や機能にアクセスしてタスクを遂行するための仕組みです。これにより、AIは自分の知識だけでは足りない場面でも、外部環境から追加の情報を取得したり、特定の機能を活用したりできます。
ツールの特徴
1. 外部環境との相互作用
AIが直接アクセスできない情報を取得するために、検索APIやデータベース、計算ツールなどを使います。
2. タスクに応じたツールの選択
解決しようとする問題に応じて、適切なツールを選びます。たとえば、計算が必要なら「計算ツール」、情報検索が必要なら「検索ツール」を利用します。
3. 動的な選択と使用
ReActエージェントは、タスクの途中で必要なツールを自動的に判断し、適切なタイミングで利用します。
例: ステップごとにツールを使って計算する場合
先ほどの「割引と値上げ」の問題を、ツールを使う形で考えてみましょう。
問題
100ドルの商品に20%の割引を適用し、その後10%値上げした場合、最終価格はいくらになるか。
必要なツール
- Subtractツール: 数値を引き算するツール。
- Multiplyツール: 数値を掛け算するツール。
- Addツール: 数値を足し算するツール。
ステップ1: 割引後の価格を計算
1. Multiplyツールで元の価格の20%を計算:
100 × 0.2 = 20
2. Subtractツールで割引額を引く:
100 – 20 = 80
割引後の価格は 80ドル。
ステップ2: 値上げ後の価格を計算
1. Multiplyツールで割引後の価格の10%を計算:
80 × 0.1 = 8
2. Addツールで値上げ額を加える:
80 + 8 = 88
値上げ後の価格は 88ドル。
ツールの応用範囲
ツールは計算だけでなく、以下のような場面にも使えます。
- 情報検索: 「検索ツール」を使って外部データを取得。
- 翻訳: 「翻訳ツール」を活用して他言語のテキストを翻訳。
- 画像解析: 「画像処理ツール」を利用して写真や図の情報を解析。
ReActエージェントがツールを使えることで、AIはより多機能になり、柔軟にさまざまなタスクをこなせるようになります。
ReAct プロンプト
ReAct プロンプトは、「Reasoning(推論)」と「Acting(行動)」を組み合わせたAIのタスク実行手法で使用される入力形式のことです。このプロンプトの形式は、AIが論理的な推論を行いながら、必要に応じてツールや外部リソースを使用してタスクを遂行するための指示を与えます。
従来のプロンプトが「質問→回答」という単純な形式だったのに対し、ReAct プロンプトでは、推論の過程や行動の詳細を含む構造が加わる点が特徴です。
ReAct プロンプトの構造
ReActプロンプトは、以下のような段階的な形式で進行します。
観察(Observation)
現在の状況やタスクに関する情報をリストアップします。
推論(Reasoning)
観察に基づいて論理的な結論を導き、次のステップを計画します。
行動(Action)
必要に応じて、ツールや外部APIを使用して行動を実行します。
結果(Observation)
行動の結果を記録し、それに基づいてさらに推論や行動を繰り返します。
ReAct プロンプトの構造
問題
「ある店舗が製品を100ドルで販売しています。その店舗が20%の割引を適用し、その後10%値上げした場合、最終的な製品価格はいくらですか?」
プロンプトの進行例
観察(Observation)
問題文を読み、製品の元の価格(100ドル)と割引率(20%)および値上げ率(10%)を確認する。
推論(Reasoning)
最初に割引後の価格を計算し、その後値上げ後の価格を計算する必要があると判断する。
行動(Action)
ツールを呼び出す:
- 「Subtract」と「Multiply」を使い割引後の価格を計算する。
- 「Add」と「Multiply」を使い値上げ後の価格を計算する。
実際の計算:
- 割引後の価格 = 100 × (1 – 0.2) = 80ドル
- 値上げ後の価格 = 80 × (1 + 0.1) = 88ドル
観察(Observation)
ツールの出力を確認し、計算結果(88ドル)を記録する。
結論(Final Answer)
「最終的な製品価格は88ドルです。」
ReAct プロンプトのメリット
論理的な思考プロセスを可視化
推論過程が明確になり、ユーザーがAIの判断を追跡しやすい。
柔軟性
ツールや外部リソースを動的に利用できるため、複雑なタスクにも対応可能。
エラー回避
ステップごとに観察と推論を繰り返すことで、間違いを減らす。
ReAct 実際の応用例
- 計算問題の解決
- 情報検索やデータ処理
- 複雑な意思決定やタスクの分解
ReAct プロンプトは、AIを単なる回答生成装置から、論理的に考え行動するインテリジェントなエージェントへと進化させる重要なステップです。
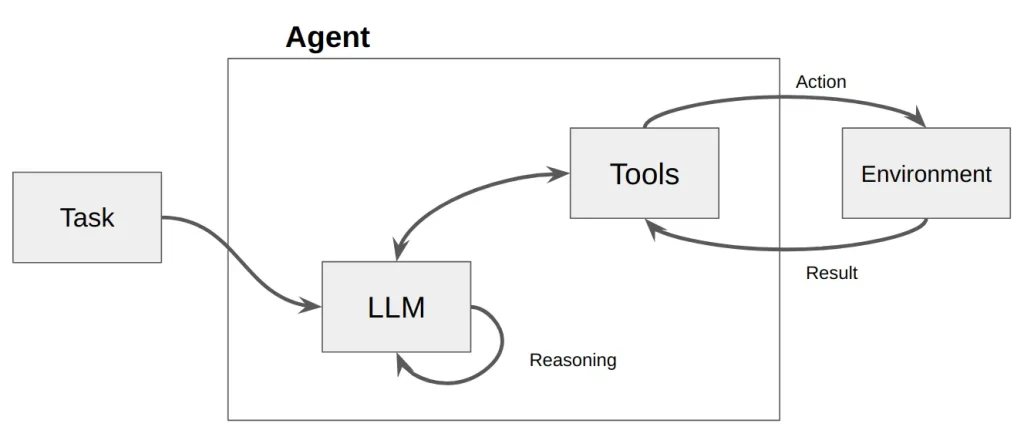
図1:ReAct エージェントのパイプライン
引用元:Using LangChain ReAct Agents with Qdrant and Llama3 for Intelligent Information Retrieval
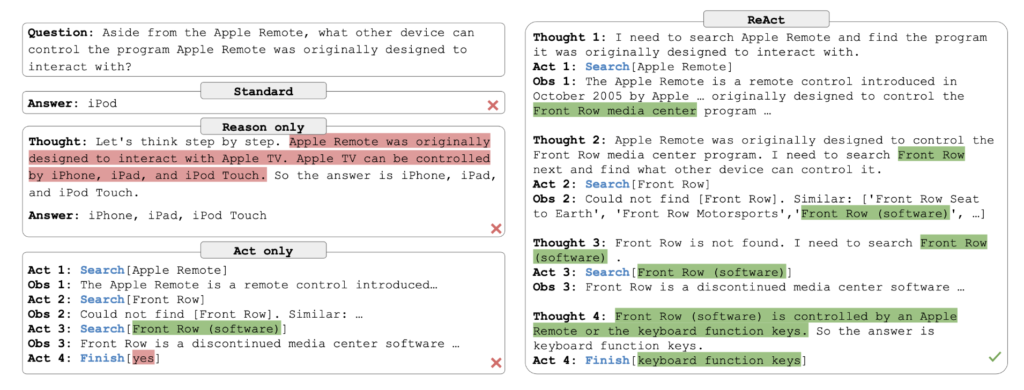
図2:ReAct 作業と他の方法の比較
引用元:ReAct: Synergizing Reasoning and Acting in Language Models
ReAct の長所と短所
長所
推論と意思決定の改善
ReACT は、LLMの推論能力を強化し、人間らしい方法で環境とやり取りできるようにすることで、深い知識推論タスクと意思決定タスクで特に優れています。
外部ツールとの統合
ReAct により、LLMは外部ツールとコミュニケーションし、外部ソースから追加情報を取得できます。この統合は実世界のアプリケーションにとって有益です。
推論と行動の相互作用
ReAct モデルは、推論トレースとアクションの間でより大きな相互作用を可能にします。推論トレースは、計画の構築、追跡、および更新、例外処理を行いながらアクションは外部からの情報収集などを行います。
適応力と回復性
ReAct はリアルタイムで自己修復および適応性を示し、システム全体の信頼性と回復能力を向上させます。
パフォーマンスの向上
ReAct は、LLMが回答を提供する前に推論を促すことにより、LLMのパフォーマンスを向上させます。これにより、正確な回答が得られます。
短所
上記の利点に加えて、ReAct にはいくつかの制限があります。
トークンの制限
ReAct の特性上、継続的な推論と行動が必要となるため、推論ステップが進むにつれてトークン数が急速に増加します。これにより、モデルが指示を忘れたり、OpenAI GPT などの料金の高いモデルでは、コストがかかります。
時間の制限
連続的な推論と行動が必要なため、回答が完了するまでに時間がかかる場合があります。この問題に対処するためのいくつかの論文が提案されています。例えば、CodeAct は、行動を余り呼び出さないようにするために生まれました。
ReAct エージェントの使用法
LlamaIndex での ReAct の動作原理
ここでは、LlamaIndex 内に事前に統合された ReAct エージェントを使用して説明します。動作原理は、ReAct エージェント内に 2 つの主要なオブジェクトが存在します。
AgentRunner
チャット履歴の管理、タスクの状態の更新などを行います。
AgentWorker
これが ReAct であり、AgentRunner からタスクを受け取り、推論およびアクションを行います。完了後は、タスクの状態をAgentRunner に返し、タスクの完了に推論ステップが必要であれば繰り返します。そうでなければ、完了状態を返し回答を提供します。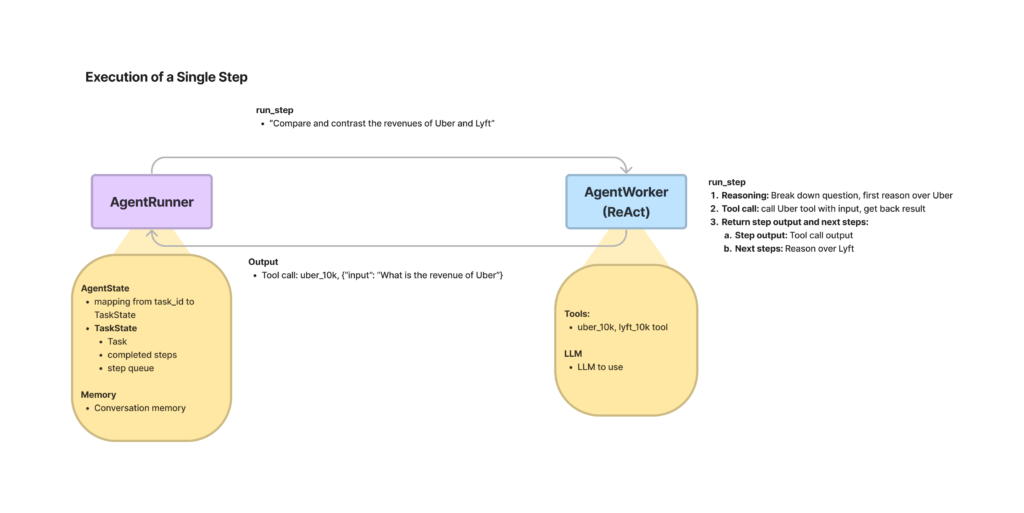
ReAct の基本コード
まず、必要なクラスをインポートします。
from llama_index.core.agent import ReActAgent
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
次に、multiply と add の 2 つのツールを作成します。
llm = OpenAI(model="gpt-3.5-turbo-instruct")
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)
上記の例では、質問に対して 2 つの推論ステップが必要であることがわかります。最初に 2 と 4 の計算を行い、次に 2 と 4 に 20 を加算します。
response = agent.chat("What is 20+(2*4)? Calculate step by step ")
結果:
Thought: I need to use a tool to help me answer the question.
Action: multiply
Action Input: {"a": 2, "b": 4}
Observation: 8
Thought: I need to use a tool to help me answer the question.
Action: add
Action Input: {"a": 20, "b": 8}
Observation: 28
Thought: I can answer without using any more tools.
Answer: 28この簡単な例では、ReAct はうまく機能し、28 という正確な回答を出力しています。
擬似コード(Pseudo-code)
# 初期設定
observation = "初期の問題やタスクを与える"
# ReAct プロセスのループ
while not done:
# 1. 推論: 次に何をすべきかを考える
reasoning = ai_model.generate_reasoning(observation)
# 2. 行動: ツールや外部環境を使用してアクションを実行
if "必要な行動" in reasoning:
action = ai_model.decide_action(reasoning)
result = tool.execute(action)
else:
result = "行動なし"
# 3. 観察: 実行結果を観察して記録
observation = f"Reasoning: {reasoning}, Action: {action}, Result: {result}"
# 終了条件を確認
done = ai_model.check_if_done(observation)
# 結果を出力
print("最終結果:", observation)
割引と値上げの計算例
問題:
「100ドルの商品に20%の割引を適用し、その後10%値上げした場合、最終価格を求める」
コード例
# 初期設定
observation = "商品価格: 100ドル, 割引: 20%, 値上げ: 10%"
done = False
while not done:
# 1. 推論
reasoning = f"現在の観察: {observation}. 次に割引価格を計算する必要がある。"
# 2. 行動
if "割引価格を計算" in reasoning:
original_price = 100
discount_rate = 0.2
discounted_price = original_price * (1 - discount_rate)
result = f"割引後の価格は {discounted_price} ドル"
observation = result
elif "値上げ価格を計算" in reasoning:
increase_rate = 0.1
final_price = discounted_price * (1 + increase_rate)
result = f"値上げ後の価格は {final_price} ドル"
observation = result
done = True # 計算が終わったので終了
# 結果を出力
print(observation)
まとめ
以上が、皆さんにすてきな方法をご紹介しました。これにより、LLM の潜在力を最大限に活用できます。この手法を使用して、Coder エージェント、コンテンツ作成エージェントなどを自由に構築できます。ただし、ReAct には長い履歴や回答時間の遅延などの課題も存在します。興味を持っていただければ幸いです。読んでいただき、ありがとうございました。